I like data. There I said it, and I am well aware of how odd that statement might make me sound. But, I do enjoy working with assessment data in regards to schools and student achievement. Accurate assessment data used wisely for this purpose is both exciting and invigorating in the valuable information which can be gleaned from it for better instruction. Can the data sometimes be used in a fashion that misleads? Sure. Can the use of testing data sometimes lead to an overemphasis on testing and “teaching the test”? When mishandled, yes. But, when used correctly, I think accurate and reliable assessment data is the clearest, most objective way to measure student learning, especially when looking at a group of students. Such data can give us valuable insight into what we might not otherwise notice on the individual student level as well. However, there are many ways administrators, lawmakers, members of the public, and teachers, while attempting to use assessment data for noble purposes, might cause inadvertent problems through the misuse of this data.
The assessment data I am referring to here is derived from standards based assessments given in a standardized format. Ideally, these tests are robust in nature, assessing students at a variety learning levels with an emphasis on higher order thinking skills. Many of the modern assessments have incorporated performance based tasks and essay style questions which are very helpful in identifying the proficiency of students to perform tasks at these higher order levels. Most assessments have at this point shifted from paper and pencil based testing to some form of computerized testing. Some of these computerized assessments also have “adaptive” elements which scale up or down pulling from a bank of questions on various levels of knowledge based upon whether a student answers a question correct (which tells the assessment to give a more difficult question next) or answers it incorrect (which tells the assessment to lower the difficulty of the next question) to “zero in” on the student’s level or knowledge. Such adaptive assessments are a particular favorite of mine as far as their ability to generate even more accurate measures of where a student is truly performing than traditional, non-adaptive assessments. These traditional assessments have a predetermined set of questions and/or tasks and lack the ability to deviate from this predetermined structure. Thus, with traditional, non-adaptive assessments the data gained is of little value to assess where a student is performing if he or she is significantly below the level of knowledge the test was designed to assess or significantly higher. Regardless of these significant differences, all of these assessments can be referred to as “standardized” tests. “Standardized testing” has almost become a dirty word with many both inside and outside of professional education. However, I feel that this is a result of the mishandling of the data and/or the preparation for the assessment rather than “standardized testing” in and of itself being something bad.
Some standardized testing is simply mandated by the state. For these state mandated tests, the local district has no choice about whether to give the assessment or not. Instead, the state mandates when to give these assessments and the manner of procedures to follow when giving it. To the best of my knowledge, prior to the 2014-2015 academic year, these state mandated tests (at least the ones used in Mississippi since the passage of the No Child Left Behind law) have consisted of one summative round of testing at the end of the course. For the high school level courses which were selected by the state for mandated testing (Algebra I, Biology I, English II, & US History), these occurred at either the end of the semester course in December (for schools using block scheduling) or prior to the end of year (for schools using traditional yearlong course scheduling). For grades 3-8 (Language Arts, Mathematics, & 5th/8th Science), the testing was always at the end of the year. During Mississippi’s one year stent with PARCC testing during the 2014-2015 year, the testing was broken into parts which occurred with more frequency than the single end of course testing given in prior years. This type of state mandated testing for all intents and purposes is “summative” in nature, meaning it is used to judge the overall learning which occurred during the course of study and was not used to actually improve learning. State mandated “summative” testing was like having a taste of the cake after it was baked. The cooking was done by that time and only the final product was being examined and evaluated for quality.
Other standardized tests are chosen by the individual teacher, school, or district. These tests are usually given periodically throughout the semester and year for “formative” purposes. Formative assessments can be thought of as “inspecting the batter” periodically while still engaged in the cake cooking process. This “batter tasting” can be used by the cook (teacher) to form a better plan for obtaining the desired appearance and taste in the final cake. Adjustments in proportion of ingredients, additions of ingredients, omission of ingredients, the intensity of mixing, and all of the steps in the cooking process can still be altered as the results are obtained (via sight, taste, or touch) along the way. The teacher gets feedback from these assessments to gauge student progress in order to make adjustments to improve learning based upon the student’s needs according to the assessment results. While I lump all of these standardized formative assessments together as voluntary, this may be somewhat misleading. The state mandates that some of these tests be given during the year as a “universal screener” to detect students that are having problems making appropriate academic gains and allowing the school and teacher to provide different instruction to the student to “intervene” in the current trajectory of learning to obtain a better result. However, even though “universal screener” tests are mandated, they are at least in theory still meant for this “formative” function of altering instruction “on the fly” while the semester or year is still in progress. Other standardized testing for supposed “formative” use might be referred to as “practice tests” modeled after the end of year, state mandated assessments or “progress monitoring” in reference to the fact that the students progress toward normal growth in academic achievement is occurring at the expected rate.
The first and perhaps most common, issue with assessment data is the overuse of testing to obtain such data. To clarify, I am referring to the constant flow of testing which takes place in some schools and districts, which has little, if any, practical usage for instruction. In summative assessments mandated by the state, this was not a huge issue when only end of semester or end of year assessments were mandated. During the PARCC era, the argument could be made that the increase in hours required for the PARCC assessments throughout the year was an undue burden which took away instructional time, but these were tests which the district, school, and teacher had no real control over as they were mandated by the state. “Universal screeners,” also mandated by the state, could be argued to be slightly burdensome as well with their periodic nature throughout the year. But, when used properly with the teacher having the training to break apart the data and examine what it is telling him/her about the individual student and the class as a whole in regards to academic progress toward the end of course goal and to alter classroom instruction using the data as a guide, the “universal screener” could be a vital tool for the teacher to tailor instruction for greater effectiveness. The same can be said for “progress monitoring” tests which often are the same type of test as the universal screener, but perhaps given at more frequent intervals during the year. When such “progress monitoring” assessments are used properly by a properly motivated and trained teacher, they can be a formative tool to alter instruction to reach desired outcomes both for the individual student and the class as a whole. What are commonly referred to as standardized “Practice tests” are preparation tests for the end of year assessment. “Practice tests” like “progress monitoring” tests can be used in this formative process to alter classroom instruction for greater effectiveness while also giving the class a simulation of the end of year test. Some schools or districts have also incorporated so-called “common assessments,” created through the collaboration of faculty to use as regular, nine weeks, or semester tests for formative purposes. When used for their formative purposes these tests can all be useful, but formative assessments are really nothing that new. Effective teachers have always used “formative assessments” to tailor their instruction in the past. Whether it be via asking for a show of hands during a lesson to answer a quick question to gauge how many in the class understood the content enough to reach the proper answer, giving “daily grade” type work to see if the students could reach a desired level of performance while still covering the topic or unit in question, or giving a “pre-test” before covering a new topic to determine the existing level of knowledge on a topic to determine how best to plan effectively to maximize learning with the individual or group, “formative” assessment has always been existed in classrooms where learning was maximized. The only real difference from those examples of traditional, informal, formative assessments and the ones we have discussed here is that they were not quite in such a standardized format and perhaps not given in such a formal fashion. But, despite this rosy picture in regards to these non-state mandated assessments being used for formative purposes, there still could be issues preventing these tests from being used effectively for their powerful, formative purpose to tailor instruction.
The most common mistake made for “progress monitoring” or “practice” testing is that the tests are given too close to the end of the course or semester. For instance, a class is preparing to take the Algebra I test at the end of the year, then two weeks before the state mandated test is given the district/school/teacher decides to give a “practice test” and the results are given back to the teacher and students on the Monday prior to the end of year mandated assessment on Wednesday of the same week. I think most people can see the major issue with this scenario. The test results are of minimal, if any, benefit to the student or teacher in this scenario since the results came too late for significant changes to be made to instruction. If results were in the hands of the teacher and students with sufficient time, real changes could be made which might alter the student’s outcome before the end of year. For example, imagine the teacher receives the results back and the class as a whole shows a problem with quadratic functions or some other topic. The teacher cannot effectively re-teach quadratic functions with essentially only one day (Tuesday) to go before the final assessment. Whereas, if the test had been given three weeks prior and the results obtained three weeks before the final assessment, several lessons could be planned to re-teach, practice, assess, and maybe even re-teach again using still another different teaching method to help the group “master” this area of weakness in quadratic equations. Instead, by making the data of little or no “formative” purpose due to the timing of the practice test, all the student, teacher, and school have in their hands is an advance preview of what the state results will be when they get them back. Instead of “inspecting the batter,” they are simply cutting a tiny sliver from the cake to taste five minutes before it is done baking. Little can be changed at that point to alter the outcome of the final product. But, I suppose, you will get to see how it tastes a little earlier. Sadly, a day or more of instructional time may have been missed in order to have this advance preview of results which has no formative value on tailoring instruction.
As hinted above, another problem with standardized “formative” assessments is that they are given too often during the actual class time. For example, let us say that a standardized assessment being used for supposed “formative” purposes takes most of a 50-minute class period and covers a large swath of objectives for the course. The decision is made to give two of these assessments per week in addition to the teacher’s normal testing schedule. This single decision made a huge impact upon available instruction time, if the assessment is given during normal class time. Not only has the cost to instructional time been large in this scenario, but if the assessment is designed to cover a broad amount of content and learning objectives for the course, much of the data is a waste in relation to the unit being covered. Just giving the assessment has cost perhaps 50 hours of instructional time over the course of the year. This might be 40% of the total instructional time available for the teacher to cover every bit of the course content over the span of the year (minus assemblies, absences, and the normal interruptions to instruction). The information obtained via data has become of little use due to the overall loss of available instructional minutes. Also, the teacher now has a steady stream of data to attempt to examine on a twice weekly basis. Between breaking this data down twice weekly, attempting to then use it to plan the altered instruction, and the missing two days of instruction per week, the odds of the teacher having time to effectively examine the data in meaningful ways to alter instruction become exponentially smaller. Standardized formative assessments must not occur with such repetition as to become overwhelming and undue burdens on instructional time. Otherwise, all you end up with is a big pile of data which I suppose looks impressive on a “wall” or inserted into a presentation graph, but had no real impact on student learning.
In the above example, the insignificant value of these broad, instructional time consuming, standardized assessments for formative purposes can be alleviated in several ways without dropping the concept altogether. First, narrow the scope of the assessments to reduce time spent testing and to make the data more meaningful for revising instruction. By trimming the standardized assessment down to only assess the content currently being covered, the data is of a more manageable volume and directly applicable to the topics being covered during the week. Second, the teacher should consider reducing other forms of assessment (the teacher’s regular testing schedule) which might be redundant to the standardized assessment. Short daily quizzes might not be needed anymore considering the frequency of this twice-weekly testing. Third, the teacher should attempt to schedule such assessments, if possible, during non-instructional time. If students have study time every day, then perhaps a segment of it could be utilized for these assessments instead of taking time away from instruction. Again, the concept of the standardized assessment, even at this exaggerated twice-weekly frequency, can be made of greater formative value by altering the variables mentioned and the many others the teacher has direct control over. Although, I will be the first to admit such a twice-weekly schedule might simply have to be reduced to a more manageable and meaningful frequency.
Another issue with the use of data is the emphasis on overall achievement versus growth. This is an area which has somewhat improved over the years, but I still see the mistake being made on a regular basis. For example, a 3rd grade Language Arts teacher has 89% of her students scoring Level 4 or above (roughly the equivalent of the old Proficient & Advanced levels) on the end of year assessments, but another 3rd grade Language Arts teacher in the school has 70% of his students score a Level 4 or above. Those examining the results data then make the statement that the 89% teacher “won” or is better at teaching Language Arts than the other teacher. Such an assumption and statement based upon this limited amount of data is so ridiculous it almost defies description! However, we still see such pronouncements made with unfortunate regularity. Again, based upon this limited data which “appears” on the surface to show one teacher “winning” over the other, there is absolutely no way to draw any conclusion on teacher effectiveness! Why? You can only judge effectiveness of the individual teacher by having some assessment data as to how well the students were performing before (and hopefully during) the time the teacher had the student(s). Without this prior “baseline” performance of the students, you have no idea whether any growth in student achievement and learning took place during the year. Imagine, what if a beginning of the year assessment had shown that 95% of the first (supposed better) teacher’s students scored an equivalent of a Level 4 or greater at the start of the year? Imagine, then that the same beginning of the year assessment data had shown 60% of the second (supposedly worse) teacher’s students scored an equivalent of a Level 4 or greater at the start of the year? Who appears to really have had the greater effectiveness teaching 3rd grade Language Arts? Would it not be the second teacher who seemed to have a greater positive impact on student achievement? The second (supposed worse) teacher grew her students enough to raise 10% more of them to Level 4 or Level 5 by the end of the year while the first (supposed better) teacher had 6% of them drop from those top two levels during the same time? Yes, of course! The second year teacher was able to demonstrate growth. The only clear way to legitimately make judgments upon performance of a group of students is to look at growth of the same students over time. Ideally, although not always feasible, this pattern should occur over multiple years as well where the same teacher/school raises achievement among multiple cohorts of students over time before judging effectiveness. Unfortunately, over and over, you still hear this error repeated with overall achievement being given as evidence of the effectiveness of instructional practices, the teacher, or the school itself instead of growth.
Is this meant to suggest there is no place for discussion of overall achievement? Is growth the only thing worth examining? What about situations where growth of the same students or a cohort is simply not available? No, growth should be the main thing, but it is certainly not the only thing worth examining. Growth should be the main goal for the student, teacher, and school as a whole. Growth should also be considered the main indicator (among testing data metrics) to determine instructional effectiveness. However, we often do not have sufficient data for judging such growth among the same student or cohort of students. Take the ACT test which most students have taken by the end of their junior year. Schools receive reports back from ACT which show the average score of students overall and in each testing area. The reports also show what percentage of the school’s students whose scores are up to an acceptable level of college readiness (meaning the students can statistically be expected to succeed in specific freshman level college courses and do not need to take “remediation” courses). However, in most schools, ACT testing is a one-time occurrence among a particular cohort (group) of students without a lower level version of the test taken to judge growth. In the absence of such “real” growth data, the next best indicator in this case is the percentage of students who are deemed college ready over several years. Why? Because the average score report given to the school showing the average composite score and average subscore for each subject can be misleading. The percent of students demonstrating college readiness would be valuable to look at over several years to determine an overall trend. If for three years or more the percentage of students demonstrating college readiness on their scores increased in all areas, then one can begin to detect a trend which is moving in the desired direction. While not perfect, if this trend continues over even more years, the school can feel a certain level of confidence that efforts in college academic preparation are probably yielding the desired result. One year gains in the percentage demonstrating college readiness show nothing as this year’s group of juniors may be more naturally academically inclined and higher scoring than the last year’s group. Two years of gains in a row could still be the result of multiple factors. Two years of gains might indicate more effective instruction. However, it might also reflect three groups with each latter group having students more naturally higher performing academically than the year prior. But, consistent gains in this percentage beyond two years become increasingly less likely to be attributed to the random chance of naturally higher achieving students and more than likely are attributable to instructional efforts. Each consecutive year that rises in this percentage occur increases the likelihood even more that it is not simply random chance of inherently higher performing groups of students. On the subject of average ACT scores, another issue altogether is the fact that up until the 2014-2015 school year not every junior actually took the ACT as it was encouraged (not required) for only those students planning on attending college. In addition, the ACT required a payment by the student for each test taking attempt (except in certain waiver situations). Since Mississippi is now offering a free testing of the ACT and the state is requiring all students to take it, ACT score reports for the school will be of far more value and have greater reliability as an indicator of a school’s instructional effectiveness.
But, you might ask why I am giving little value to ACT average composite and average subscores? If you notice, I did point to the percentage of students taking the test whose scores indicated a readiness for freshman level college coursework as the preferred indicator and not average scores/subscores. The reason is that the average score is of little significance for instructional planning or to judge success of anything instructional. Sure, it is great to be able to brag on your average scores being high or gaining over time. I have even personally engaged in such bragging when the school I worked with had such gains in average scores. However, average scores in general are of the least value of all testing data because they are so easily skewed. To illustrate this, imagine there are two small schools (School A and School B) with senior classes of ten students each and all took the ACT last year. School A has an average ACT score of 21 among all its senior class. School B has an average score of 20 among its seniors. The temptation would be to say that School A outperformed School B, after all it does have the higher average score. Now, forgetting the main issue that the ACT at most schools has no baseline from which to determine growth, let us see why saying School A “outperformed” School B is misleading regardless and percentage of test takers meeting college readiness mentioned in the previous paragraph is by far preferable. These averages do not show you that School A with the better average of 21 had the following student scores: one student with 36, one student with 34, one student with 32, three students with 18, two students with 15, and two students with 10. On the other hand, School B with the lower average of 20 had the following student scores: one student with 29, four students with 20, and five students with 19. Assuming for the sake of argument that a score of 19 is needed to attend the closest university, which school had the best performance based upon this one year in preparing its students? What if this breakdown repeated itself in a similar fashion over several years? School A had the highest average score, yet only 30% of its students scored high enough to gain college admission. School B had the lowest average score, yet 100% of its students scored high enough to gain admission to the college. I think it is without dispute that School B has the more desirable outcome and could be prouder (based on this one year’s results) of its college preparation instructional practices than School A. Still, I cannot overemphasize; this would be even more valuable to draw conclusions from for evaluation purposes, if the trend kept occurring over multiple years.
This logic is why the National Assessment of Educational Progress (NAEP) scores released a few weeks ago which showed Mississippi 4th graders led the nation in gains since 1990 (http://djournal.com/news/mississippi-fourth-graders-lead-nation-in-2015-naep-gains/) is important, but must be understood in its proper context. First, Mississippi is still in the bottom tier on overall 4th grade reading scores meaning it is ranked near the bottom again in average achievement. Second, Mississippi made more improvement over this length of time than any other state’s 4th graders tested in reading in the nation (on average). Third, this was over multiple years (15). Thus, the data in the article is not ideal as it does not track the same children over time (growth of a cohort of exiting3rd to 4th, then 4th to 5th, etc.) The data in the article is also not on the next preferred level which would be the percentage of students who met the national average score (percentage achieving a specific target) and, even better, whether that percentage actually went up over time. The data shows our average score (however the scores were distributed) went up more than the national average score went up over a ten year period. Yes, it is an overall indicator of “good” things. Yes, it is certainly better than a lack of such growth. However, more information would be needed to see how these scores were distributed which could give us an indicator of how effective our instruction is at educating all students. But, I will certainly “take it” as an overall positive indicator, despite its limitations.
The same can be said for the PARCC assessments taken in the 2014-2015 school year which were released a few weeks ago for high school Algebra I and English II tests. The state rightfully emphasized two main figures. First, the number of students scoring Level 4 or Level 5 on the assessment was the main indicator of desired performance. This was very important considering the PARCC assessment had a number of states included and anything above a Level 4 demonstrated the student was on grade level not just based upon our judgment as one state. Level 4 could be considered (in an extremely loose sense considering our old tests had a rather arbitrary division of performance levels with no national or multistate consideration of where these “cut scores” between levels occurred) the equivalent of Proficient on our old forms of state testing and Level 5 as the rough equivalent of Advanced. The state accountability model, by which our schools are graded/ranked, emphasizes the level of students reaching these two levels as well with the goal being for 100% to reach Level 4 or above. Also of note, there is no growth data available among the same students or even from the same school for these test results. This is with good reason since it is the first time (and only time) the PARCC assessments have been used. In the absence of growth, the next ideal thing to examine is the percentage reaching mastery (in this case grade level performance). Thus, the percentage reaching Level 4 or Level 5 was the ideal way to assess schools using the available data. Second, the state gave the percentage passing (in this case a Level 2 or above). This figure is important as well since it demonstrated the percentage who met the minimum score level to pass the course without looking for additional factors for help. The only problem with pass rate and why I prefer it to be the secondary consideration is that our goal as a state is not for our students to be Level 2, but for them to be Level 4 or above. Another problem with the passing percentage (and the reason it should not be looked at as the primary indicator like percentage scoring Level 4 or above) is that it is misleading since many students taking the state tests in either Algebra I or English II are not in a “regular diploma” program. Instead, they may be pursuing a “Certificate of Attendance” or an “Occupational Diploma (MOD).” Both of these programs are available for students with recognized disabilities and both do not require a student to pass these state tests with a minimal score to move on. Thus, a school might show 10% as failing to pass the Algebra I test with a Level 2. But, with a class size of ten students that might mean one student with a disability making a regular diploma impossible did not pass the test. If the student was on an alternate diploma track due to the disability mentioned, he/she would still be on track to get the alternate certificate or diploma without retaking the test. Even regular diploma students are now able to incorporate other factors than simply a passing grade on this one test to allow them to achieve a “passing” level on this one test. In my opinion, this makes the percentage of students taking the test who scored a Level 4 or Level 5 the ideal measure to “rank” districts and schools as to performance on this test. I believe the way the data was presented indicates that the Mississippi Department of Education also sees Level 4 and above percentage as their primary indicator. Below is a breakdown of Mississippi high schools on the PARCC English II 2014-2015 results, ranking them according to this combined Level 4 & Level 5 percentage.
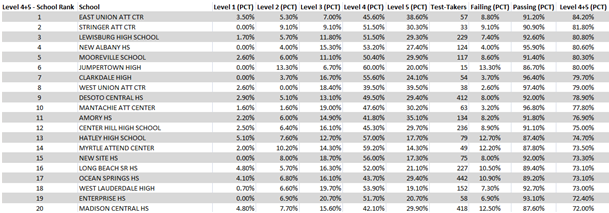
Again, we are lacking two very important elements needed by administrations to derive sound instructional decisions. The first and most desirable being growth of the same students or cohort for multiple years and the second and next desirable being change in percentage scoring Level 4 or Level 5 from one year to the next in the same grade (despite being different students). The only way for such information to be obtained is for our state to settle upon a consistent form of end of year, summative, standardized testing and keeping it for a minimum of three years. This would give you the baseline data needed to begin determining growth over time. As it currently stands, we have last year’s 2014-2015 PARCC assessment results being released now which lack a baseline from the previous year (excluding 5th Science, 8th Science, Biology I, & US History which are still state developed). In the subsequent year of 2013-2014, Mississippi gave its own MCT2/SATP tests in Language Arts and Mathematics for the last time. This year Mississippi will give Questar assessments in Language Arts and Mathematics for the 2015-2016 year since it has dropped out of PARCC and our one-year contract with Pearson. This will mean that the results we receive next year, based upon this year’s Questar testing, will lack any truly comparable and usable data for growth once again in Language Arts and Mathematics. I look forward to hearing about the Questar testing and hope it is a robust, rigorous, and accurate test. But, Mississippi I think one can see why Mississippi desperately needs stability in our curriculum and the form of state mandated end of course and end of year summative testing. As a state, we need this stability of comparable tests over multiple years to once again have accurate growth data as a base for sound data-based instructional decision making. The public also deserves consistency in these assessments so that they can pick up the paper to look at score results without hearing confusing details of why the data does not show a complete picture of a school’s or individual student’s performance in regards to growth. Without a consistent type of assessment over multiple years, the public is apt to draw false conclusions about the performance of our schools’ and individual student’s performance.
In summary, standardized testing can be an invaluable, objective tool for formative instructional decisions in our classrooms and schools by allowing students to engage in learning activities literally tailored to their individual and collective needs. However, prudence as to the frequency and manner of our non-state mandated testing practices and the use of the resulting data is a necessity to insure it yields these desirable results and does not hinder the instructional process it means to aid. Logical reasoning on the conclusions we attempt to reach based upon assessment data and how we present this data to the public is of the utmost importance to maintain transparency to our stakeholders and to make sure our limited resources are being used in ways which the data indicates they will be most effective. Finally, as a state we must work to have consistency in our form of mandated summative assessments so that our students receive tangible returns on the people’s investment. Assessments and the data they yield have the potential to be one of the most powerful tools at our disposal to guide and improve instruction. However, when close examination and logical reasoning are not used to tease out the true conclusions from such data and to make sure it aids (instead of hampers) teachers’ efforts in the classroom, such assessments are a waste of millions of dollars and a pit of instructional time which is used to cover up ineffective, arbitrary decisions within our school systems.
-Clint Stroupe
